Kafeido-Accelerator
An performance-driven AI workload, optimized for high-performance inference at scale, supported with KServe and Kubernetes.
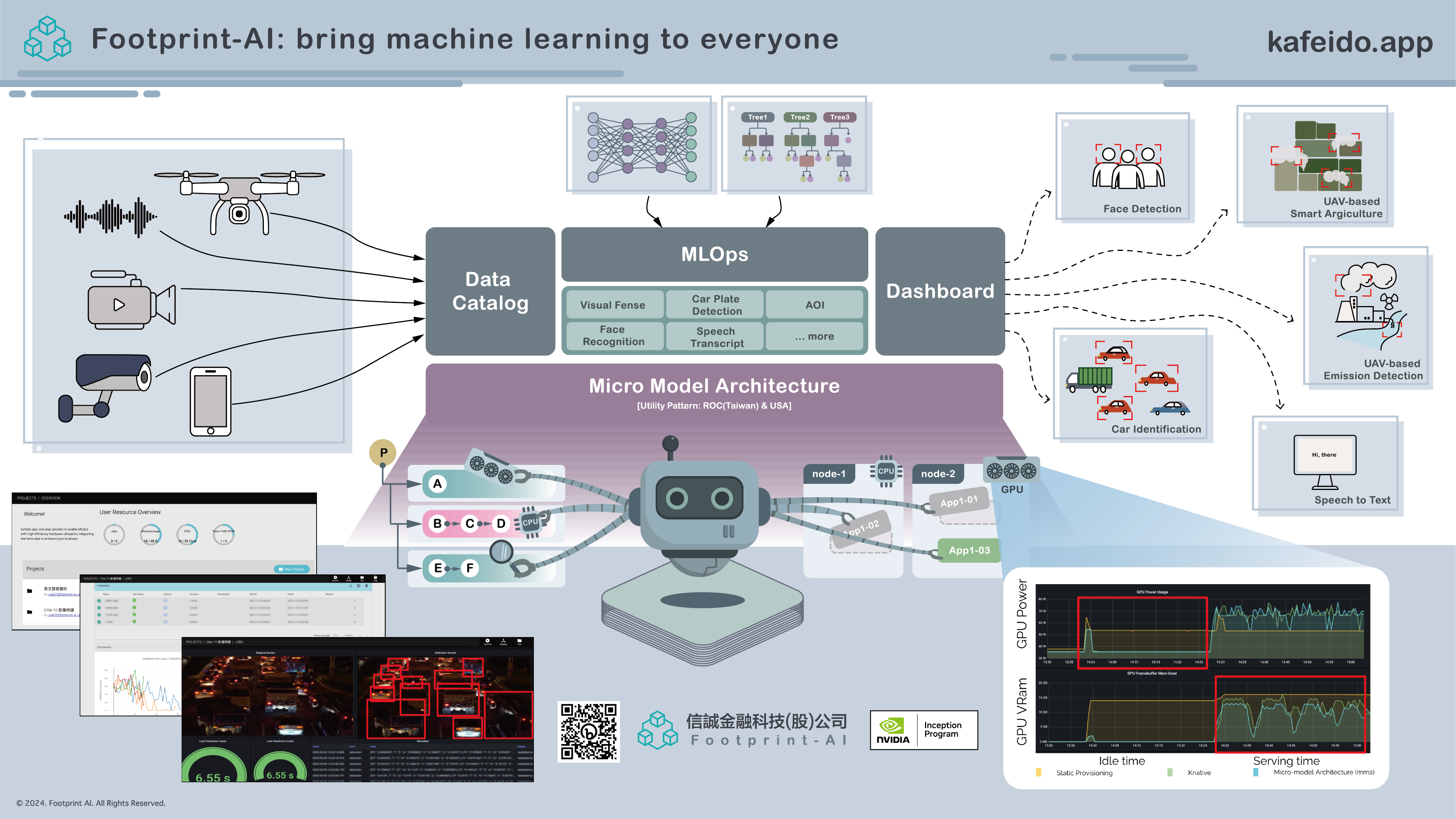
An performance-driven AI workload, optimized for high-performance inference at scale, supported with KServe and Kubernetes.
Built on top of KServe for serving multiple ML models on Kubernetes with advanced orchestration capabilities.
Offered Python SDK for seamless integration.
Optimized for low-latency, high-throughput model serving with automatic scaling based on demand.
Built-in security features with authentication, authorization, and end-to-end encryption.
Comprehensive monitoring and logging for model performance, resource usage, and predictions.
Advanced model version management with canary deployments and A/B testing capabilities.
Experience high-performance model serving with enterprise-grade reliability and sustainability.
Request a Demo
Bring Machine Learning to Everyone.
Footprint-AI focuses on a sustainable AI/ML platform, specializing in large-scale data analysis, MLOps, green software, and cloud native.
 Home
Home