Kafeido-mlops
Enterprise-grade MLOps platform that organizes GPU resources and AI models efficiently, with seamless deployment options for both on-premise and cloud environments.
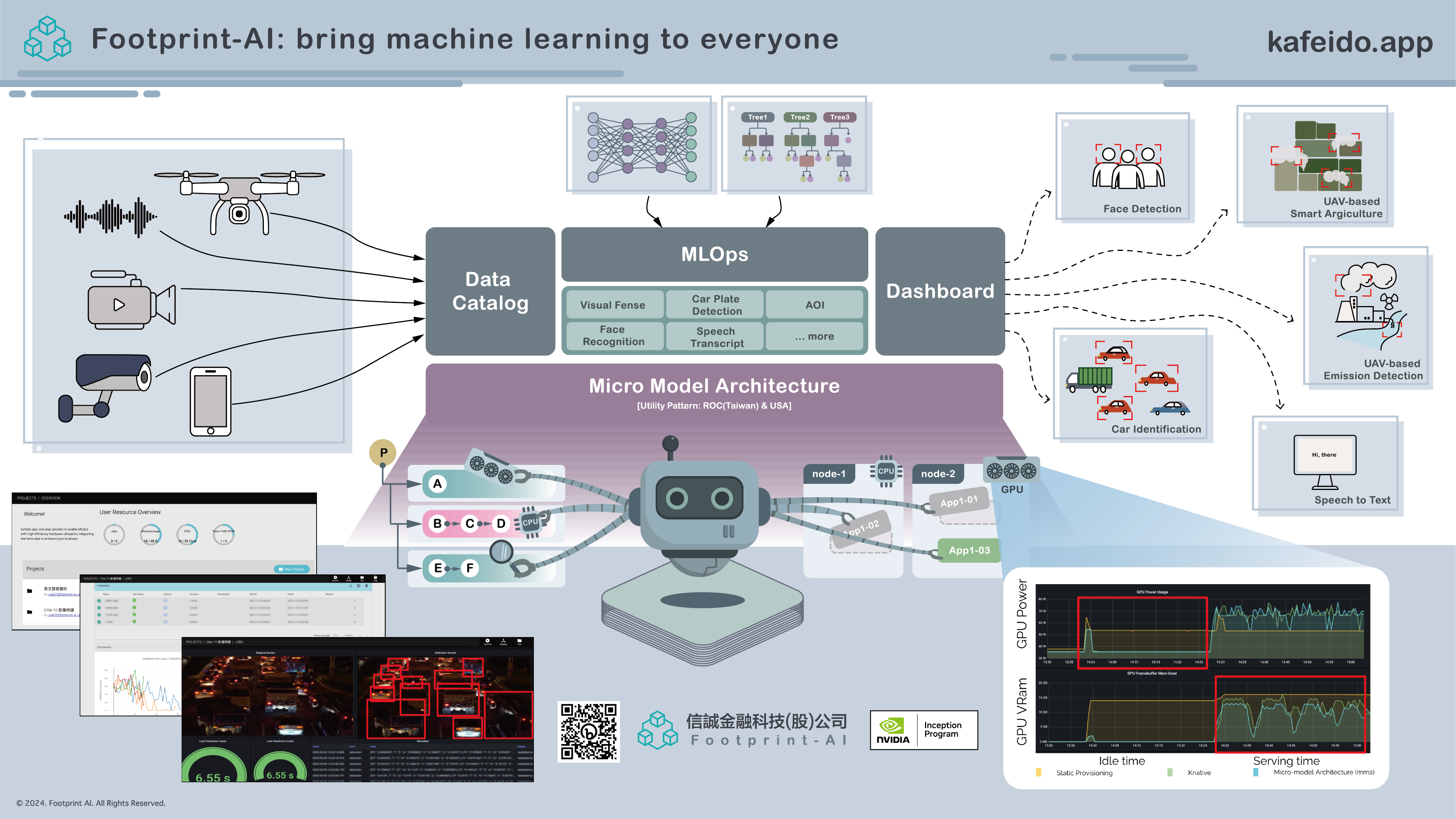
Enterprise-grade MLOps platform that organizes GPU resources and AI models efficiently, with seamless deployment options for both on-premise and cloud environments.
Efficiently organize and allocate GPU resources across your AI/ML workloads for optimal performance.
Deploy seamlessly on-premise or in the cloud, supporting flexible infrastructure strategies.
Full support for OCP backed by Red Hat and comprehensive Kubeflow API integration.
Centralized management and version control for all your AI models in one platform.
Reduce AI/ML infrastructure costs while maintaining high performance and scalability.
Accelerate your organization's move to AI generation with enterprise-ready tools.
Manage multiple AI projects and teams with centralized GPU resource allocation and model management.
Accelerate AI research with efficient resource sharing and experiment tracking capabilities.
Deploy AI models for quality control, predictive maintenance, and process optimization.
Join leading enterprises that trust kafeido-mlops for their AI/ML operations
Schedule a DemoEmpowering enterprises with sustainable AI/ML infrastructure solutions. Our kafeido.app platform helps organizations optimize GPU resources, reduce costs, and accelerate their AI transformation journey.
 Home
Home